Extend
The Extend skill lets you combine the contents of one dataset with another dataset. This can be helpful when you gather data from separate sources but want to analyze all of the data as a single dataset.
Format
Extend has several formats:
Extend (the current dataset | the dataset <source dataset>, <version>) with the dataset <target dataset>, <version>. Combines the source and target datasets using the shortest join path possible through connected datasets. If no join path exists, columns that both datasets have in common are used as join columns instead.Extend (the current dataset | the dataset <source dataset>, <version>) with the dataset <target dataset>, <version> and keep all unmatched values. Combines the source and target datasets using a column that both datasets have in common while also keeping any rows in either dataset that didn’t match.Extend (the current dataset | the dataset <source dataset>, <version>) with the dataset <target dataset>, <version> matching nulls. Combines the source and target datasets matching null values.Extend (the current dataset | the dataset <source dataset>, <version>) with the dataset <target dataset>, <version> where <predicates>. Combines the source and target datasets using the specific predicates given.
If you extend one dataset with another dataset, without a shared column or a designated primary/foreign key relationship, the resulting operation, a Cartesian product, is computationally expensive and time-consuming. It can result in a very large dataset. DataChat prompts if you wish to continue with this unusual request, and returns a Cartesian product if you click "Yes".
Parameters
When extending one dataset with another, you can use the following parameters to specify how the two datasets should be combined:
source dataset(required). The name of the source dataset.target dataset(required). The name of the target dataset.version(optional). The version of the source or target dataset to use.keep all unmatched values(optional). If this parameter is used, all rows are kept even if they don’t have a matching value in the common column.predicates(required). Operators used to compare two values. SeeComputefor more information.
Output
If the datasets are successfully combined, the resulting dataset becomes [dataset]_Extend.
If the datasets cannot be combined, an error message appears in the conversation history.
Examples
Consider two datasets, one called “Titanic” and another called “TitanicExtra.” Both datasets contain the following columns:
- Age. Their age.
- Gender. Their gender.
- Name. Their name.
- PClass. Their class.
- Cabin. The passenger’s cabin ID.
- Survived. Whether they survived the disaster.
If you wanted to simply combine these two datasets, enter Extend the dataset Titanic with the dataset TitanicExtra. This combines the two datasets using all of the columns as join columns.
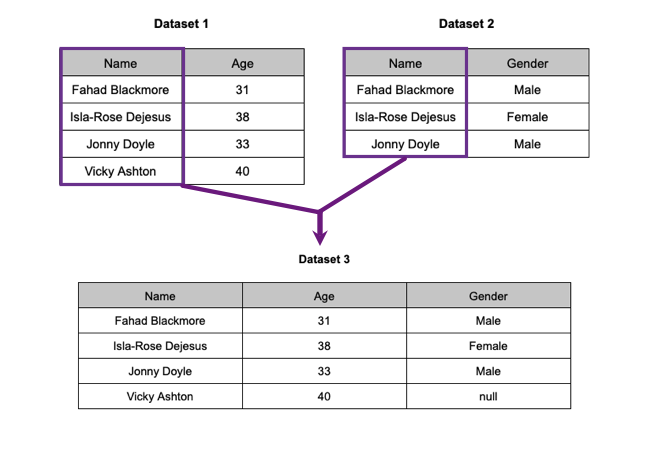
Since Dataset 2 did not include information about Vicky Ashton's gender, the gender value for Vicky Ashton in Dataset 3 is null.