Use Rename, Keep, and Join
In this example, we'll explore two datasets, learning how to keep or drop specific columns and extend datasets together to test our hypothesis that a country's overall happiness is affected more by alcohol consumption than by GPD per capita.
Load Data
To get started, click on the links below to download the 2018 World Happiness Report dataset and the 2018 Alcohol Consumption dataset.
Now we can Load the datasets into the session. We now see two datasets that look like this:
Alcohol Consumption dataset
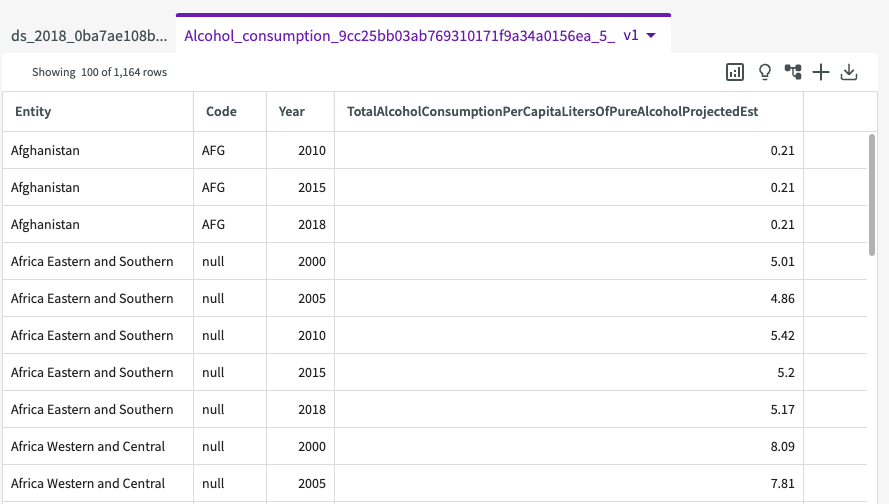
This dataset contains the following columns:
- Entity. The country.
- Code. A code given for the country name.
- Year. The year of the study.
- TotalAlcoholConsumptionPerCapita. The total alcohol consumption per capita.
World Happiness dataset
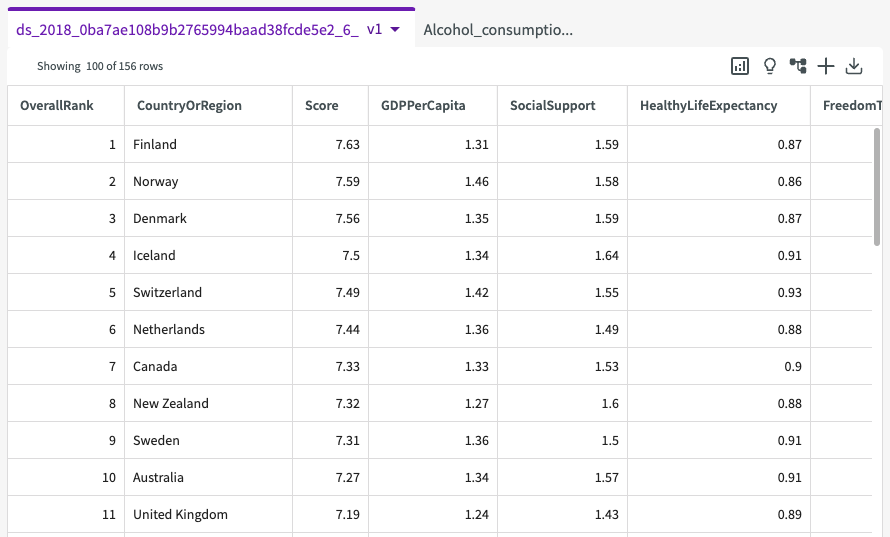
This dataset contains the following columns:
- OverallRank. The rank of a country's happiness compared to others.
- CountryOrRegion. The country or region.
- Score. The overall happiness score.
- GDPPerCapita. The GDP per capita.
- SocialSupport. How much support the country provides.
- HealthyLifeExpectancy. The average life expectancy.
- FreedomToMakeLifeChoices. How much freedom one has to make life choices.
- Generosity. How generous their fellow citizens are.
- PerceptionsOfCorruption. How corrupt the country appears to be.
Rename Datasets
The names of our datasets contain a lot of random characters and are not very clear. Before moving forward, let's rename them to "Alcohol_Consumption" and "Happiness2018". To rename the datasets:
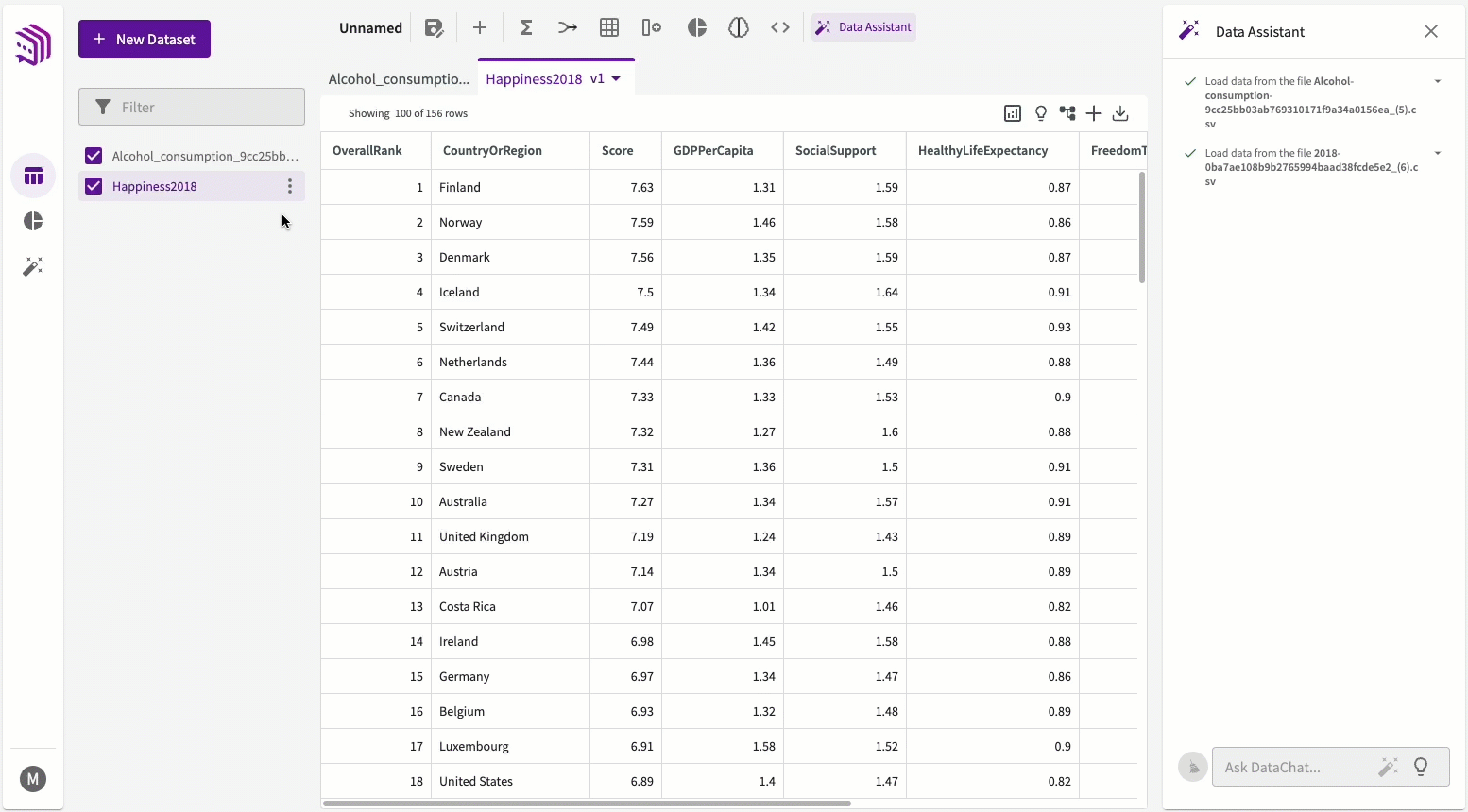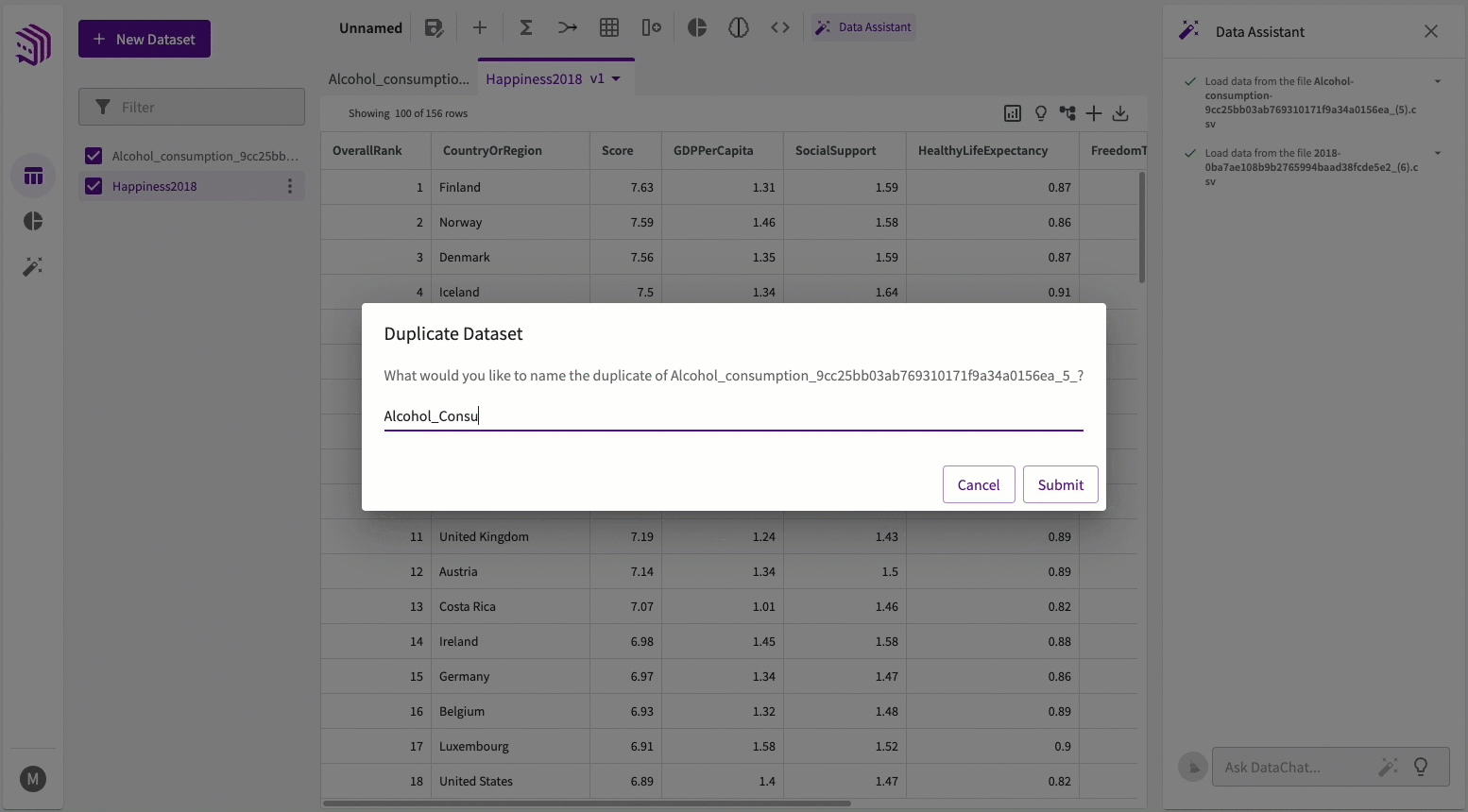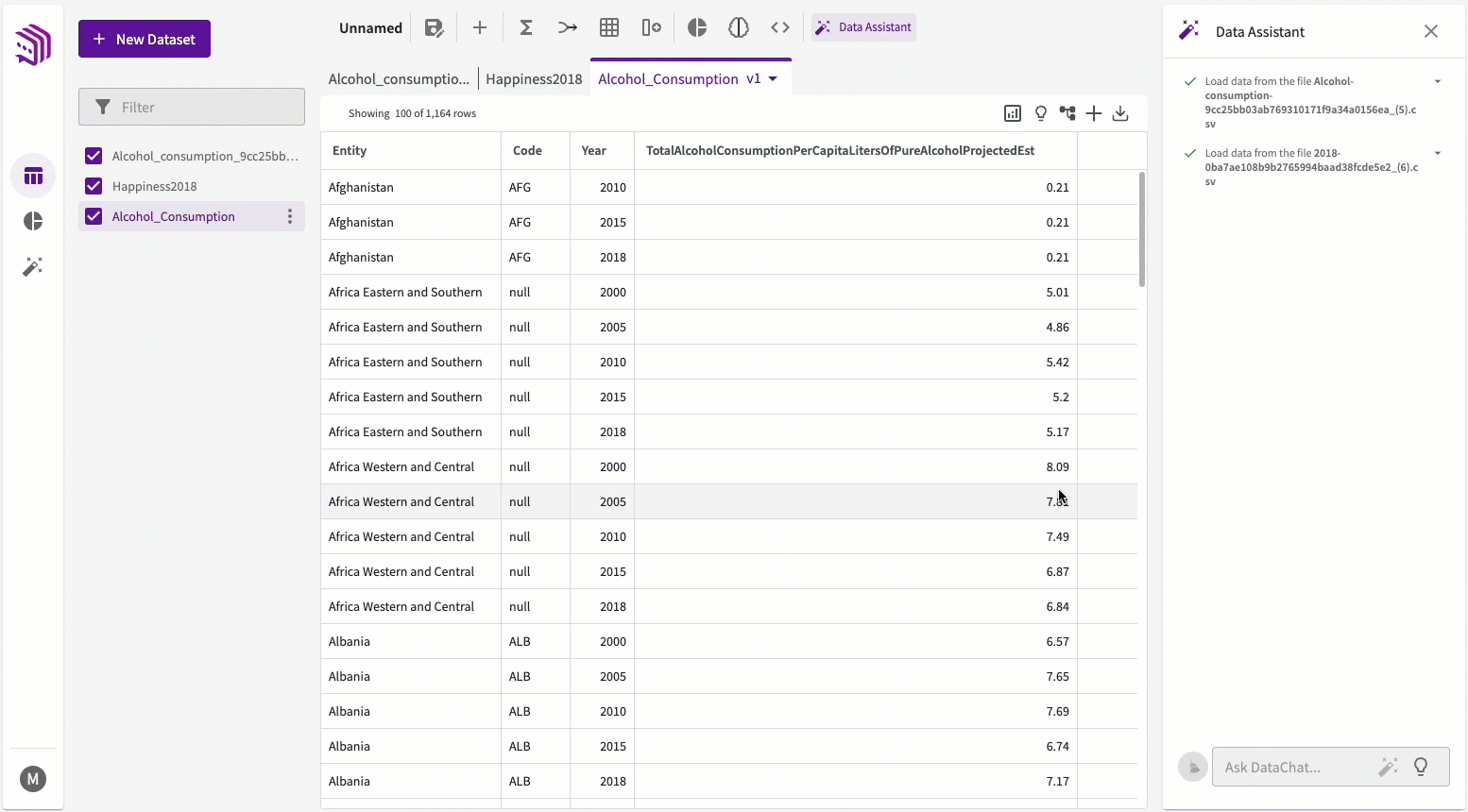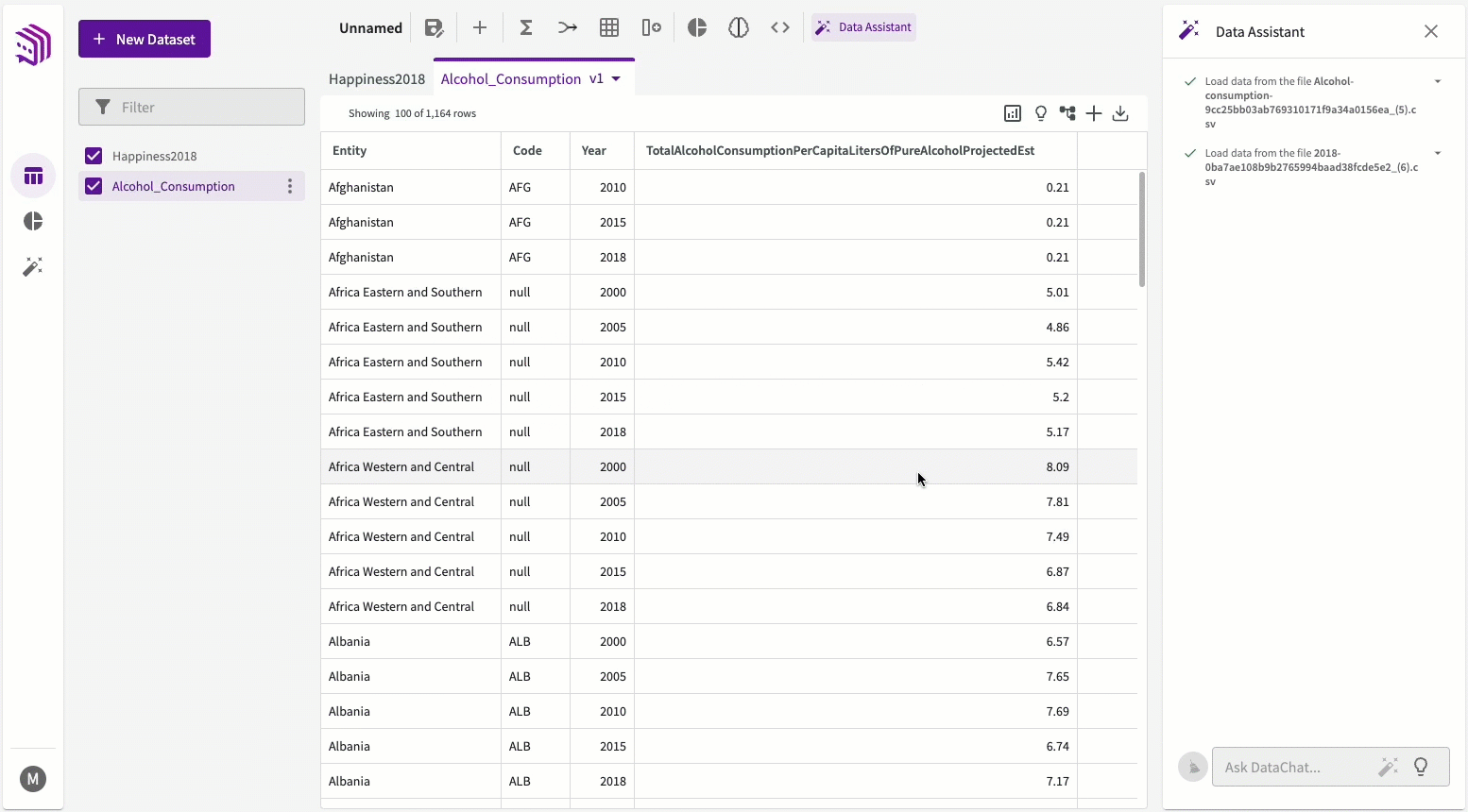
- Click the More menu of the dataset name from the list of datasets on the left.
- Click Duplicate.
- Enter the new name for the dataset and click Submit.
- Delete the old version.
Clean Our Data
To be able to analyze how alcohol consumption affects a country's overall happiness, we must first clean and wrangle our data to make sure it's ready to use with machine learning.
2018 World Happiness Data
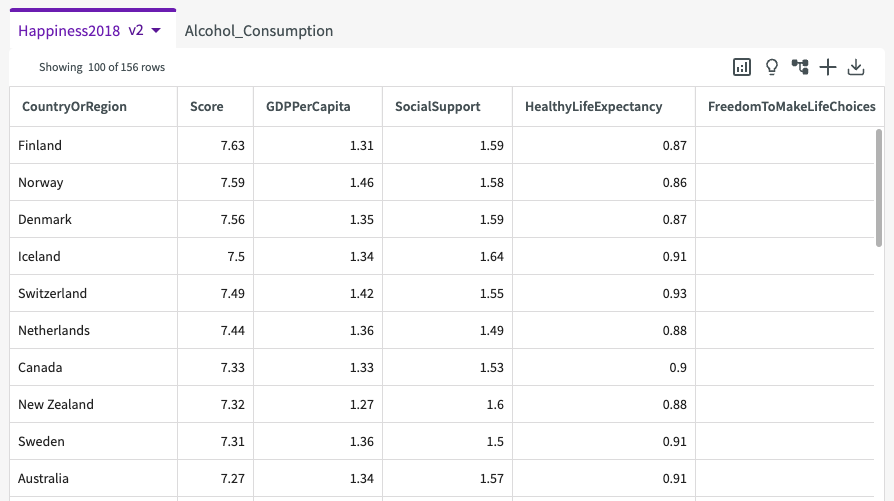
We can now begin cleaning the Happiness2018 dataset. Currently, our dataset has information that we don't really need in order to analyze the impact alcohol consumption has on overall happiness. Let's drop the unneeded columns:
- Click the More menu of the "OverallRank" column.
- Click Drop.
Now our dataset no longer has the OverallRank column:
Alcohol Consumption Data
We can now begin cleaning our other dataset. Lets make sure we're working with the right one. Click the dataset name, "Alcohol-Consumption" to make it the current dataset.
Like our Happiness2018 dataset, this dataset has information that we don't really need in order to analyze the impact alcohol consumption has on overall happiness. Since we only want data from 2018, let's use the Keep Rows skill to keep only the rows we need:
- Click Wrangle > Keep Rows in the skill menu.
- Enter "Year" for the column, "is equal to" for the expression, "the value" for the value type, and "2018" for the value.
- Click Submit.
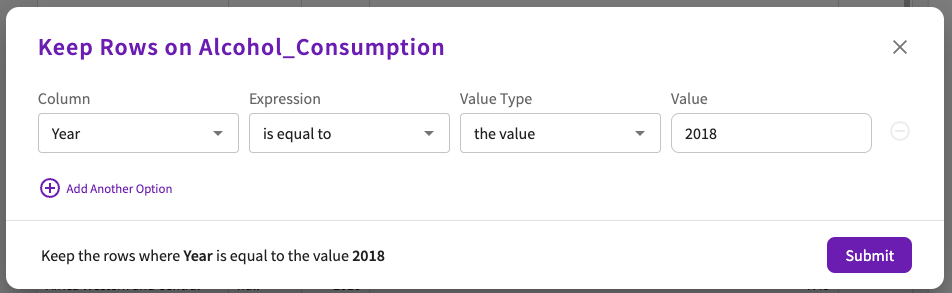
Now we see a dataset with reports from only the year 2018.
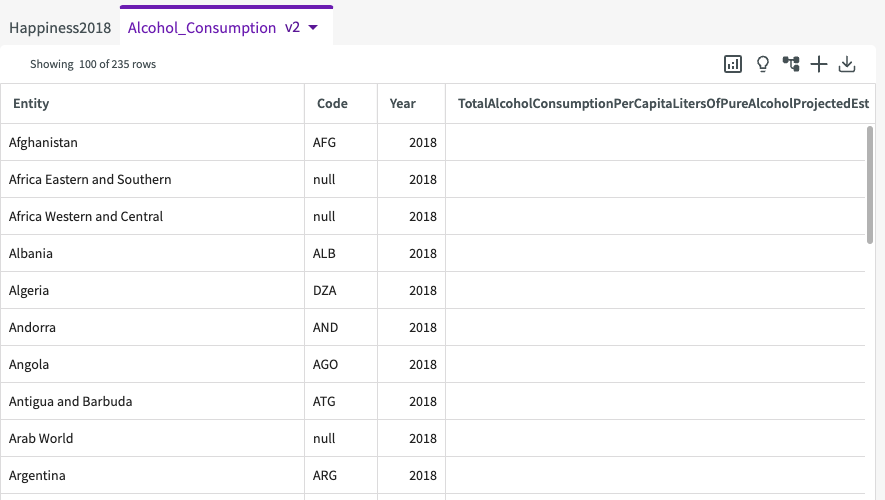
From here, we can also Drop columns we don't really need to analyze, including the columns Code and Year. To drop columns:
- Click Wrangle > Drop Columns in the skill menu.
- Enter "Code" and "Year" for the columns.
- Click Submit.

Our dataset now looks something like this:
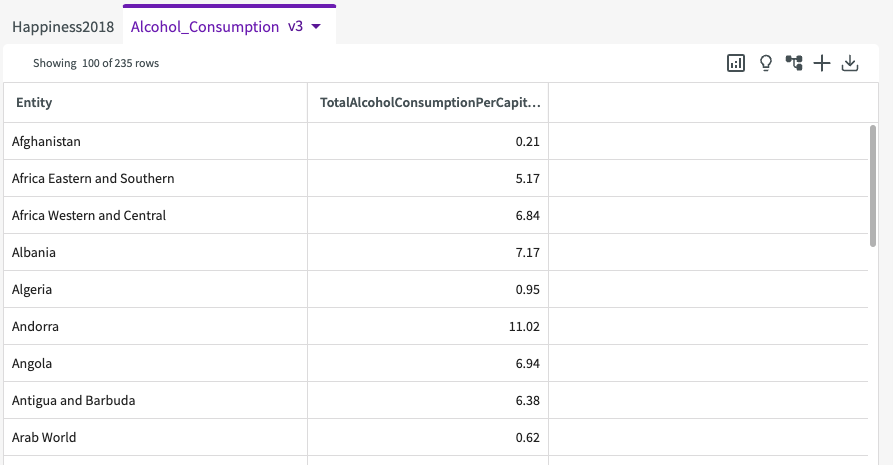
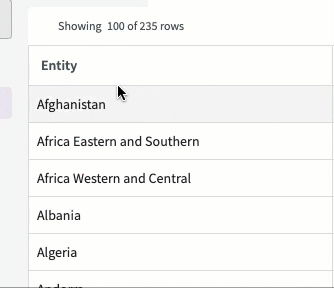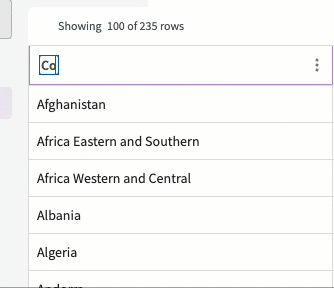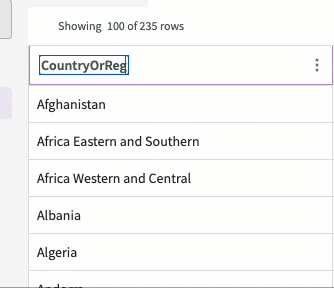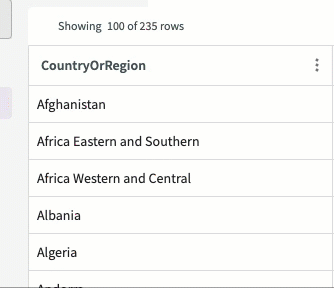
From here, we can use the Rename skill again to match the column names for the countries between the datasets. This will make it easier to join the datasets later:
- Double-click on the column name "Entity".
- Enter "CountryOrRegion"
- Press Enter.
Join Our Data
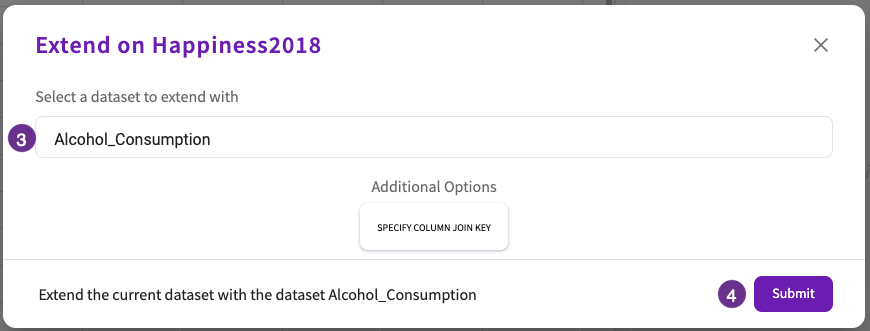
From here, we can now combine the our two datasets using the Join skill. This way, all of the relevant information can be found in one dataset.
Let's join the cleaned 2018 World Happiness Dataset with our cleaned 2018 Alcohol Consumption dataset:
- Click the "Happiness2018" dataset to make it the current dataset.
- Click Combine > Join in the skill menu.
- Enter "Alcohol_Consumption" for the dataset to join with.
- Click Submit.
The new dataset should look something like this:
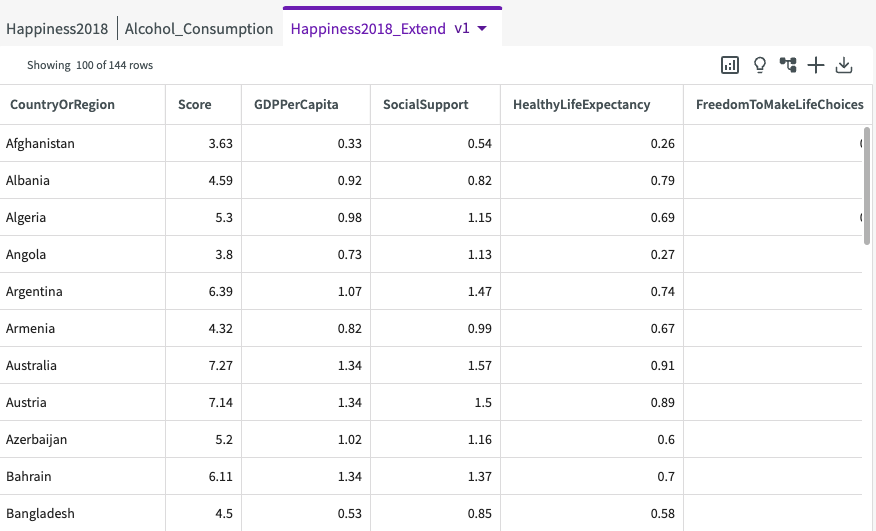
As you can see, TotalAlcoholConsumptionPerCapita has been added to the Happiness2018 dataset, and is now called Happiness2018_Extend.